In "Scientific American", December 2013, it said of reading texts in general that "When we read, we construct a mental representation of the text that is similar to the mental maps we create of terrain and indoor spaces". Students new to programming may have trouble when facing source code if they create inappropriate maps. I think that the more linear (more like prose) the code is, the easier it is for these students to understand. If execution starts at the top of the file, and ends at the end, so much the better.
Some deviations from linearity are fairly easy for beginners to understand because they're like those used in prose. Difficulties arise when the same part of text is executed multiple times, and/or when there isn't 1-to-1 mapping between the script and behaviour. In one exercise that we give students, we provide the source code of a function to simulate rolling a single dice - int RollDie() - and ask them to write a routine to simulate rolling 2 dice for a board game. Rather than write a function that returns RollDie() + RollDie(), some students create 2 copies of RollDie(), calling them RollDie1() and RollDie2(), then write a function that returns RollDie1() + RollDie2(), so that the conceptual 1-to-1 mapping is preserved. In this case, the fact that real world objects are being simulated may complicate the picture, but using rather more abstract maths proofs as a model introduces other misunderstandings.
In this article I'll consider how some features of C++ hinder the type of mental representation that students are used to. Conceptually, the text of a program is more like assembly instructions for flat-pack furniture than a novel. I'll also point out how some analogies to illustrate how languages work don't help - maths in particular can be a "false friend".
Loops
Small loops aren't too hard to understand - a temporary eddy in essentially linear code
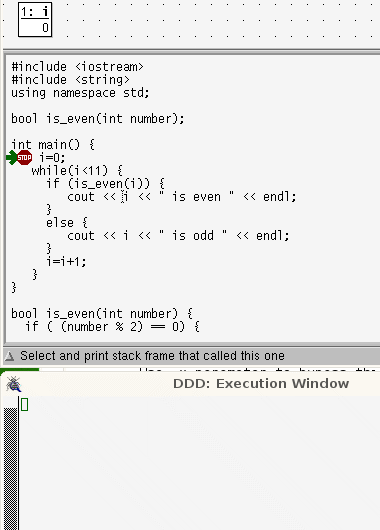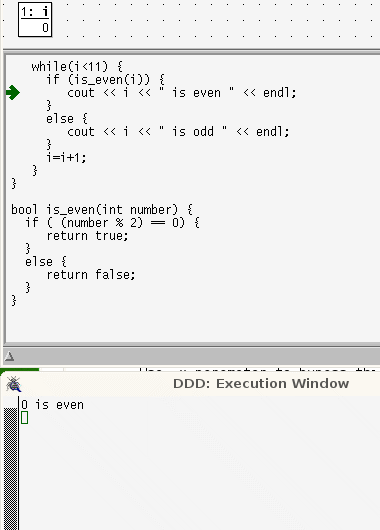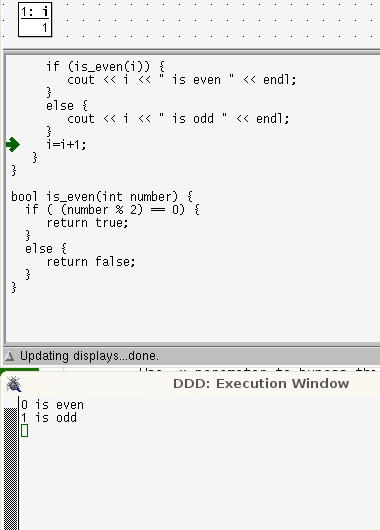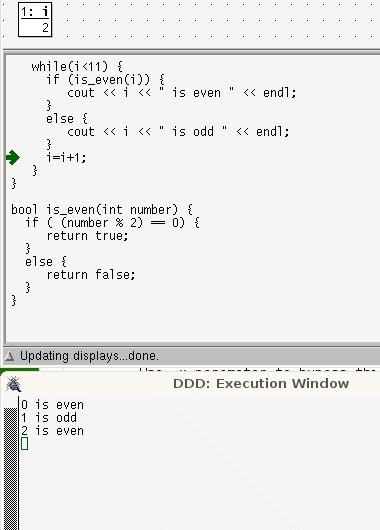
 while loops are more linear than for loops. In a while loop the lines that are repeatedly run are contiguous and in order; control takes only one step back.
while loops are more linear than for loops. In a while loop the lines that are repeatedly run are contiguous and in order; control takes only one step back.
 In a for loop, the locus of control passes through the terminating condition, the body of the code, then back to the last statement, then back again, to the terminating condition before executing the body code again
In a for loop, the locus of control passes through the terminating condition, the body of the code, then back to the last statement, then back again, to the terminating condition before executing the body code again
Functions
As far as locus of control is concerned, simple functions aren't too bad. They're rather like footnotes - you jump to them and jump back again, carrying on from where you left off. Conceptually you can in-line them. Recursion is more complicated - essentially, multiple copies of the recursing code have to be imagined if the one-to-one correspondence between text and action is to be retained.
False friends - maths and time
- After
int y=2; int x=y*3; y=4;
what value has x? People familiar with maths might give the answer 12, because they treat x=y*3 as a symbolic assignment, x being re-evaluated whenever needed. - In a maths proof, variables are usually symbolic, and at any time can have any value. In contrast, variables in languages like C++ always have a particular value. In
int i=0; while (i<3) { cout << i; i++; }the single textual i variable in the expression i<3 has successively the values 0, 1, 2 and 3. The value changes in a way that the value of maths variables don't. The text in a proof is usually processed linearly - a particular i always means the same thing. Exceptions are in "proof by cases" where the reasoning branches (the "4-color problem" was solved using such a proof - a computer program), and "proof by induction".
Discontinuities
The distance between a language and its meaning is emphasised when a small change in the language can greatly change behaviour (and vice versa). C++ has several problems of this nature.
-
int x[12];
creates an array of integers whereasx[12];
doesn't create an array. It refers to a single element in an array, one which isn't in the array created using int x[12];. - The following loop
int i=0; while (i<3) { cout << i; i++; }terminates, whereas the similarint i=0; while (i<3); { cout << i; i++; }runs forever. -
The lines
char c='0'; int i=0; string s="0";
produce variables that all look exactly the same when printed using cout, though they're not the same at all. -
The lines
if (x < 4)
andif (x << 4)
do different things. The meaning of "<<" depends on context - here it bitshifts but with cout it does something different. It never means "a lot less than".
Conclusions
- Introduce students to while loops before for loops.
- The use of flowcharts might help students who are processing the source code as if it were prose. Alternatively, it might help to use a debugger as a code-animator - see below
- Code-folding editors are useful - they offer a way to make existing code into a "black-box" once it's stable, so that students don't become distracted by verbose detail.
- Avoid recursion
- If the meaning of something depends on context, the students need to be able to identify the limits of that context
- Be prepared to introduce the idea of idioms. If you're learning English, then analysing the phrase "It is raining" down to the word-level is unhelpful - "what does it refer to?" is a linguistics question. Similarly, breaking down something like
while(fileInput >> str) { cout << str ; }into its constituent parts can easily be overdone by beginners who've been told to analyse, but haven't been told when to stop - "what is inside an ifstream"? They do need to know that it reads successive words from a file into the string called str until there are no more words left.
No comments:
Post a Comment